What is Assemblix?+
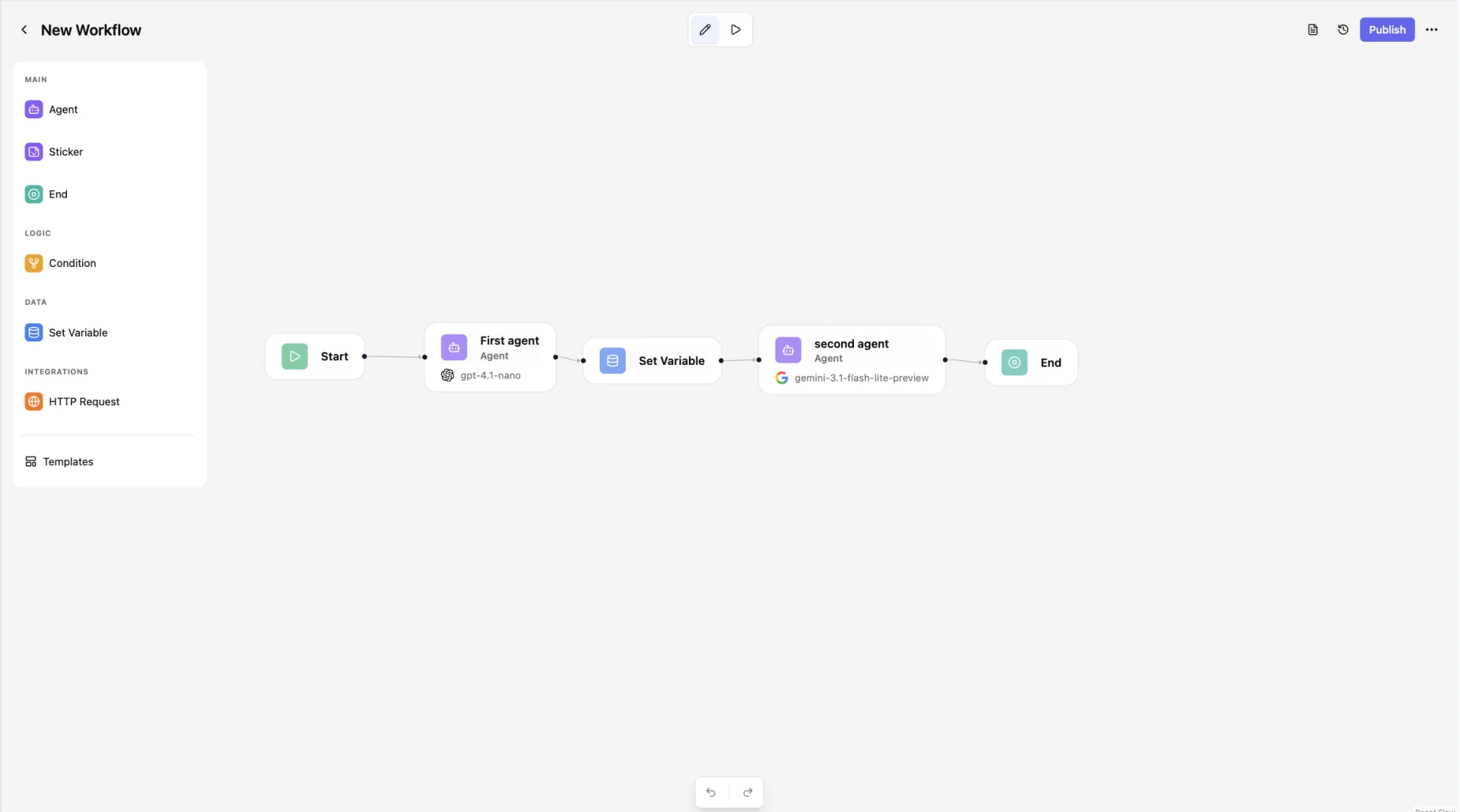
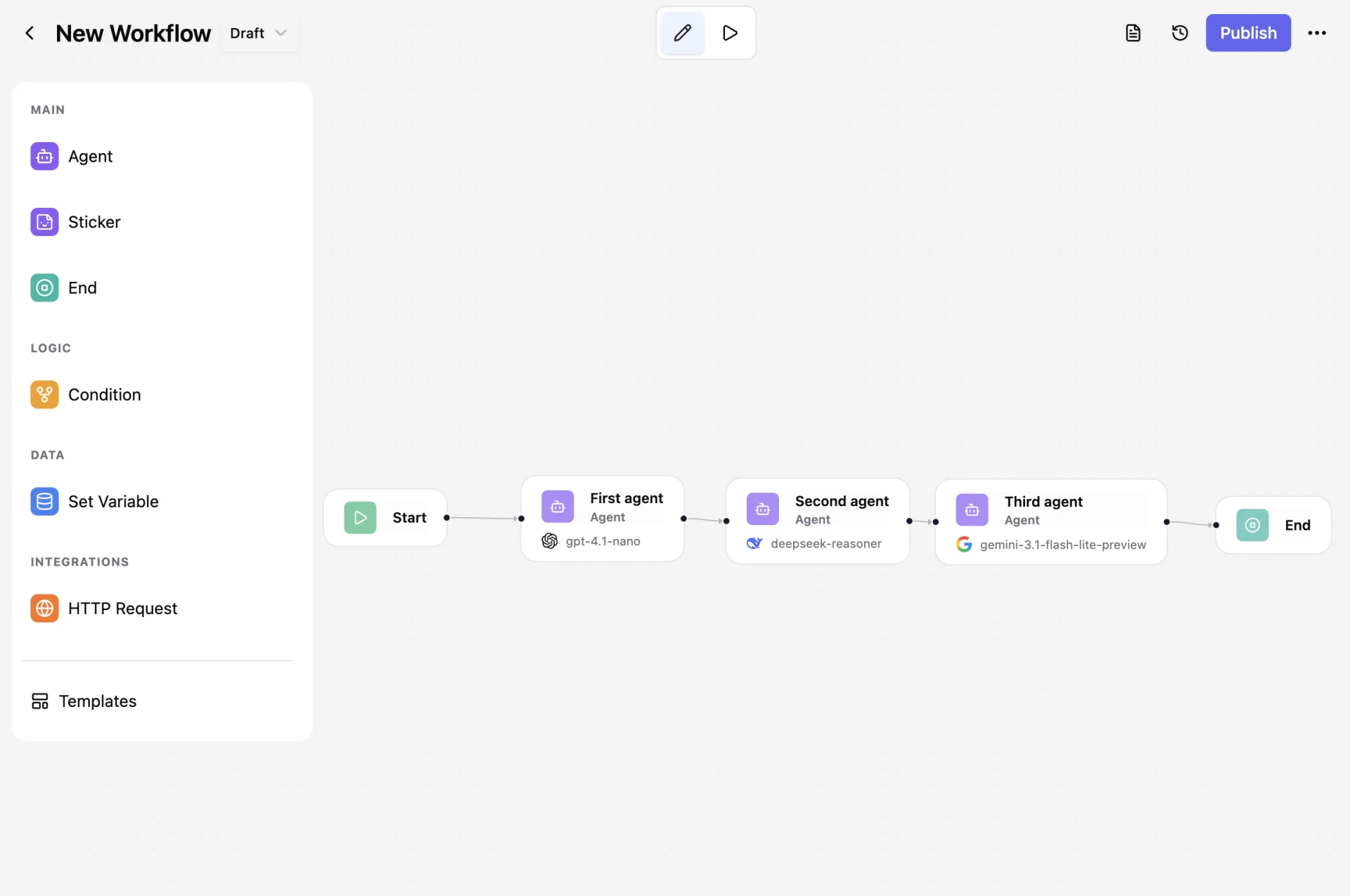
Assemblix is a visual builder for AI workflows with a production runtime. You assemble a workflow from nodes (LLM agents, tools, state updates), define a typed input/output schema, and Assemblix exposes the workflow as an authenticated HTTP endpoint. Your backend calls it like any other API.
How is Assemblix different from Flowise, Langflow, and n8n?+
The core difference: every workflow automatically becomes a typed HTTP endpoint with auth, versioning, and observability — no separate deploy step or infrastructure code. Persistent state survives restarts and weeks of inactivity. Multi-provider routing across OpenAI, Google Gemini, DeepSeek, and GigaChat with automatic fallback chains is built in, not bolted on. And it's source-available — self-host the whole stack with one docker compose up.
How do I call an Assemblix workflow as an API?+
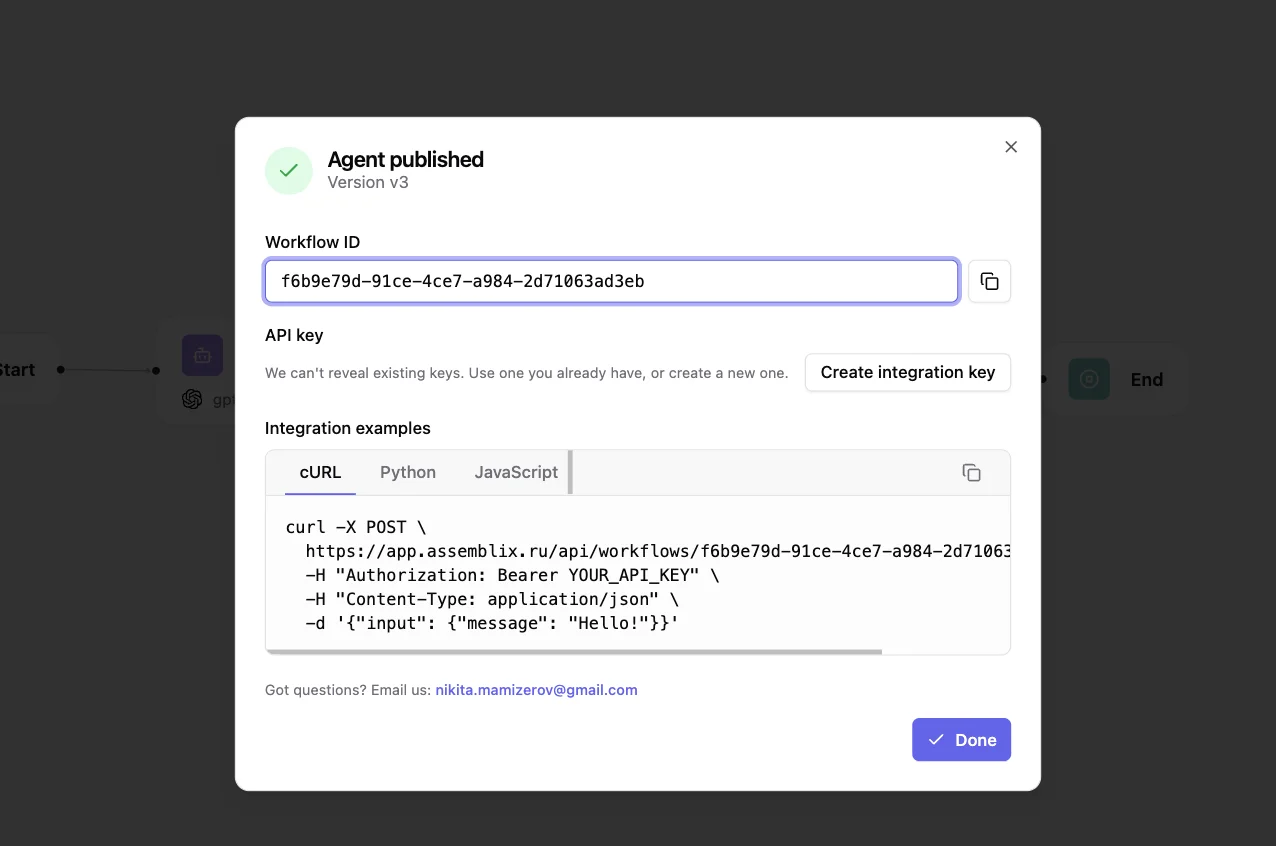
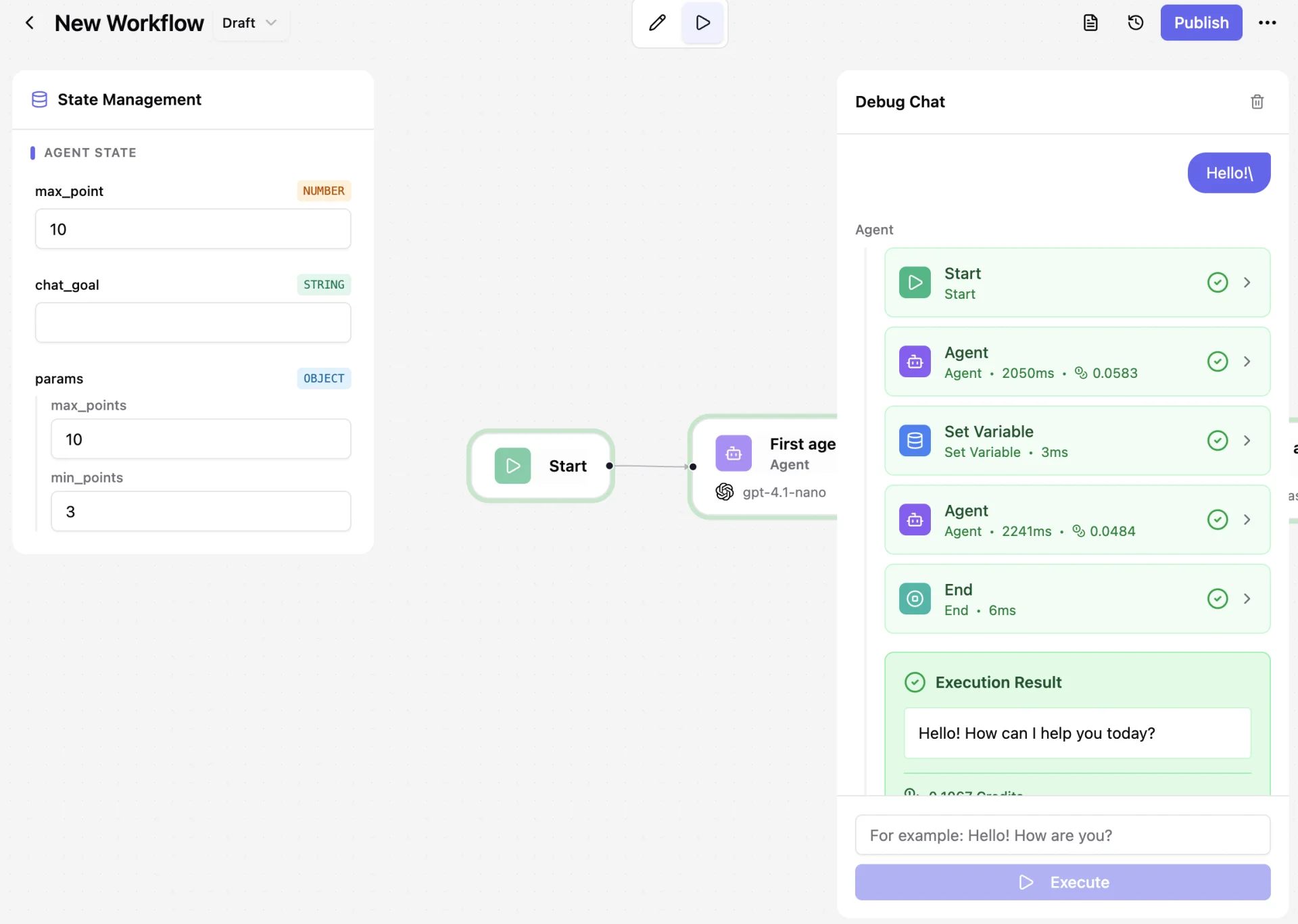
Send a POST request to /api/workflows/{workflow_id} with a Bearer token. The body carries input (matching your typed schema) and an optional state object. The response is a typed JSON payload with output (including parsed_message and tool_executions), executionId, status, updated state, and metadata (durationMs, totalSteps). Every run is traced and inspectable via /api/executions/{executionId}.
Which LLM providers are supported?+
OpenAI, Google Gemini, DeepSeek, and GigaChat. Provider is selected per node, with automatic fallback chains (e.g. openai → gemini on rate limit). Free tier ships one provider; Pro and Team unlock all of them with fallback.
What is persistent state and how does it work?+
Persistent state is the variables, memory, and cross-workflow values that survive between calls — across restarts, deploys, and weeks of idle time. State lives in Postgres, is accessible from any node via state.set/get, and supports memory windows (e.g. memory.window: "30d"). It's what lets you build long-lived assistants that remember session context.
How much does Assemblix cost and what's in the Free tier?+
Free is $0 forever: 3 workflows, 3 endpoints, 1,000 API calls per month, 1 provider, community support. Pro is $29/mo: unlimited workflows, 50,000 calls, all providers with fallback, durable runs up to 30 days, priority support. Team is $99/seat/mo: 250,000 calls, RBAC, SSO, audit log, SLA. No hidden seats, no credit card required for Free.
Can I self-host Assemblix?+
Yes. Assemblix is source-available (MIT + Commons Clause). Clone the repo at github.com/nmamizerov/assemblix and run docker compose up — a Postgres-only core, no phone-home, bring your own provider keys. The commercial billing layer is a separate Enterprise license and off by default. Prefer managed? Cloud is available at app.assmblx.com.
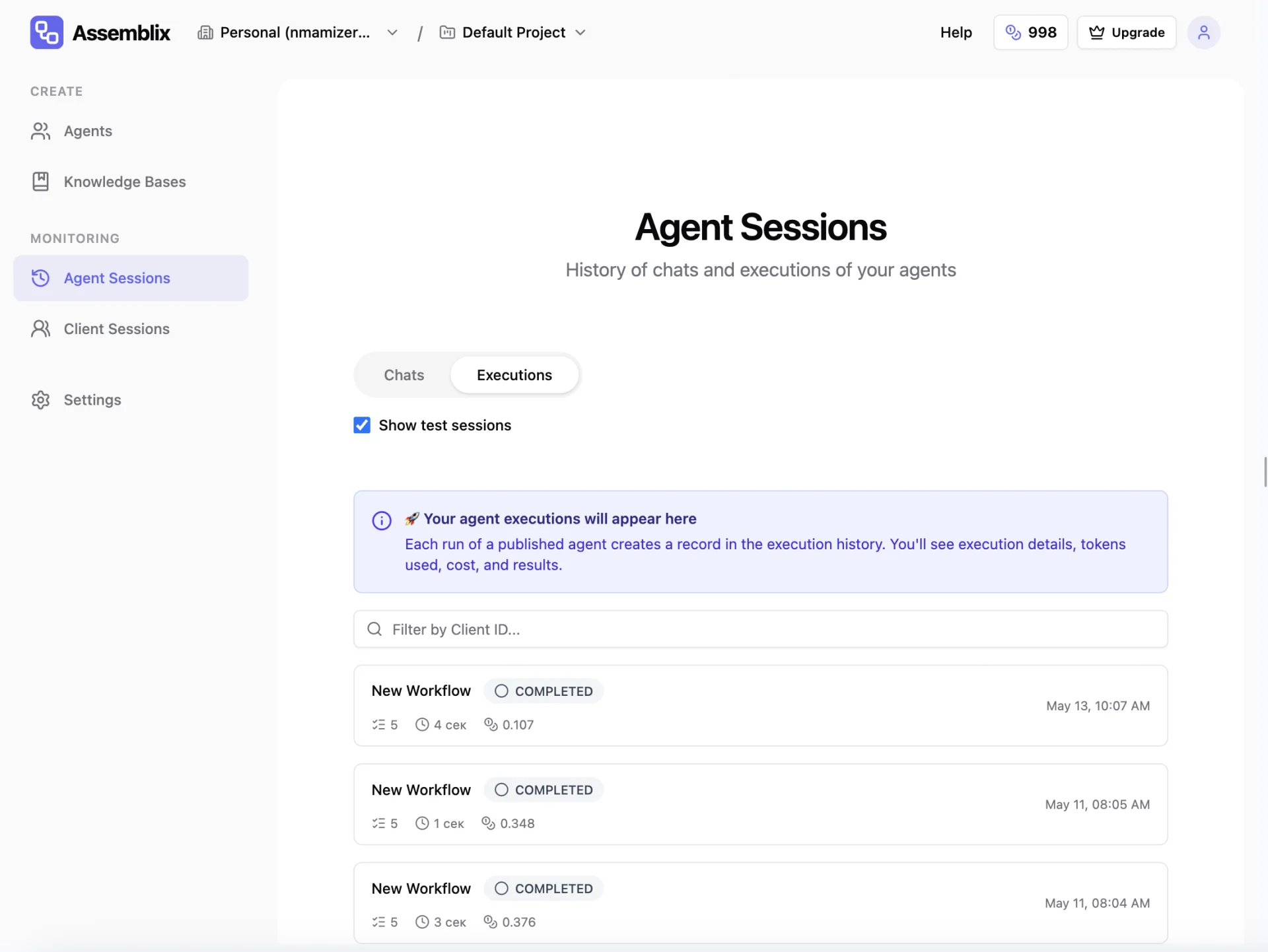
How does observability and run logging work?+
Every workflow run is traced automatically: which nodes executed, in what order, token usage, latency (durationMs), tool_executions performed, and cost (creditsUsed, ownKeyCostUsd). Inspect a single run via GET /api/executions/{executionId} or aggregate metrics across the whole endpoint. Available on every tier including Free.